A data analysis pipeline for shotgun mass-spectrometry proteomics.
Open source and targeted at the needs of academic core facilities.
Developed at UT Southwestern Medical Center & the University of Oxford.
A data analysis pipeline for shotgun mass-spectrometry proteomics.
Open source and targeted at the needs of academic core facilities.
Developed at UT Southwestern Medical Center & the University of Oxford.
CPFP has not been actively developed since 2014, when I left the proteomics group at UTSW. To access up-to-date algorithms for the analysis of proteomics data, other tools would now be preferred. However:
David Trudgian - 2019/01/03
CPFP: the Central Proteomics Facilities Pipeline is an analysis pipeline for shotgun proteomics data. It's based on tools from the Trans-Proteomic Pipeline. and allows shotgun LC-MS/MS data to be searched using multiple freely available MS/MS search engines, validated with tools from the TPP and quantified with various software.
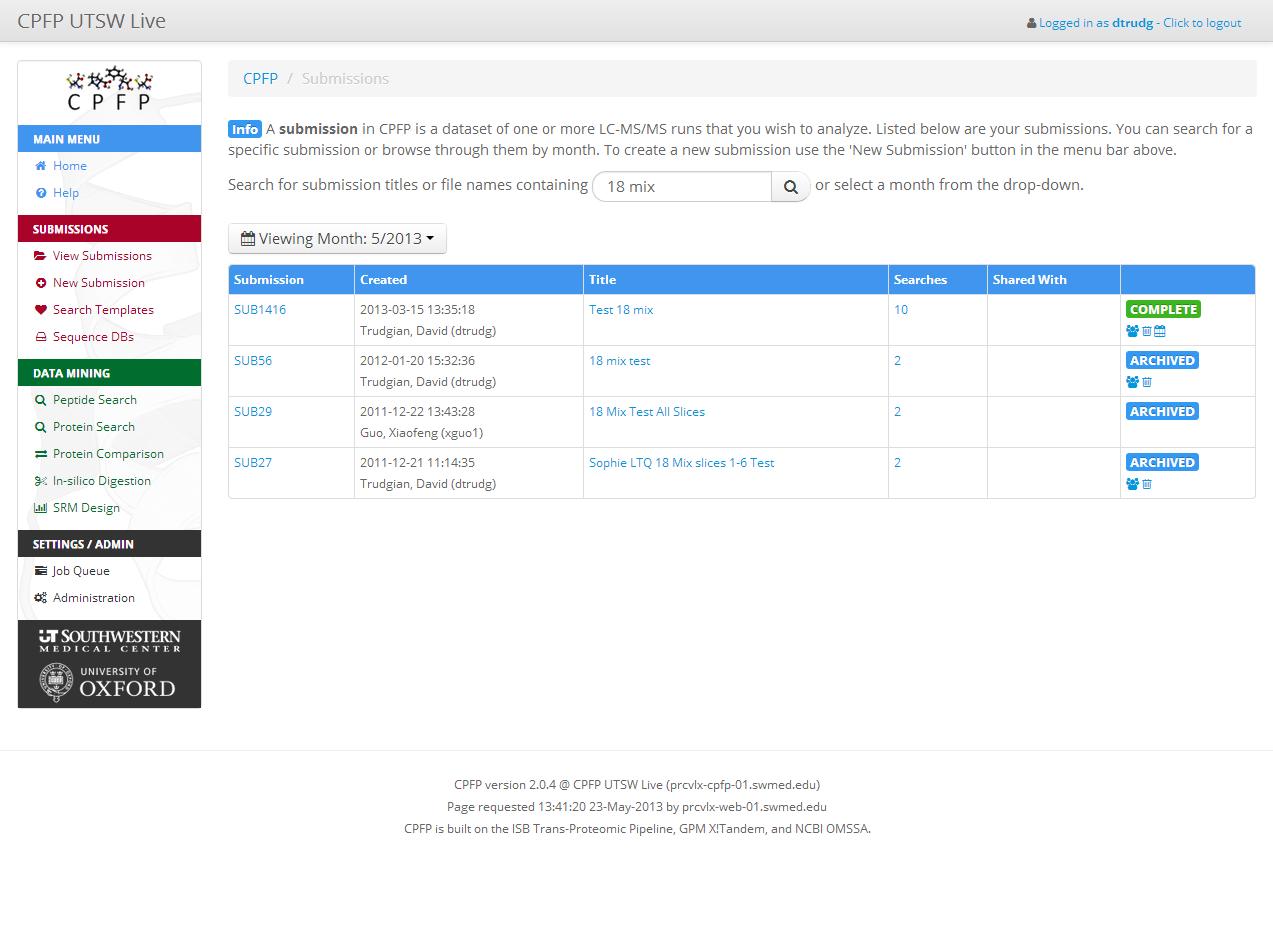
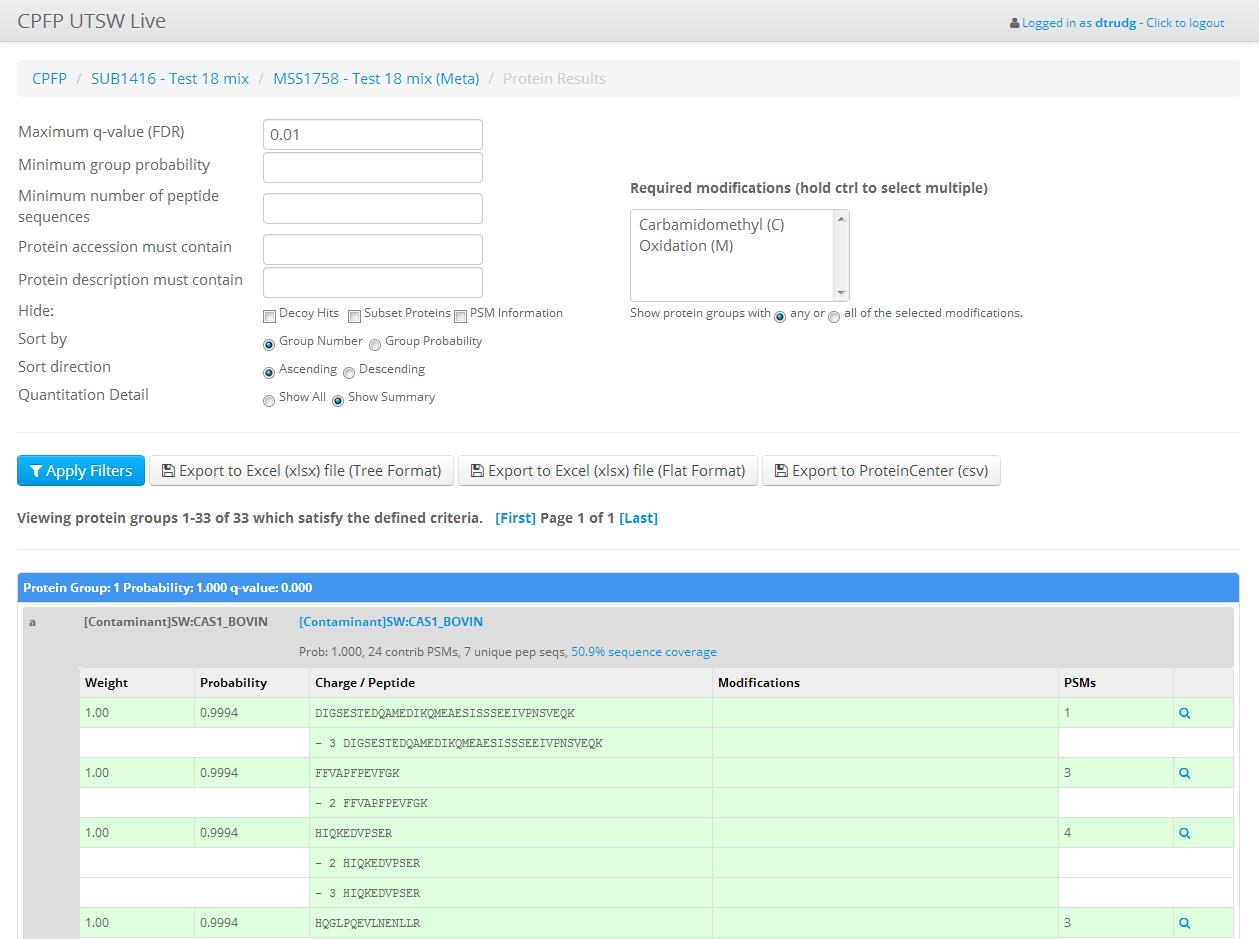
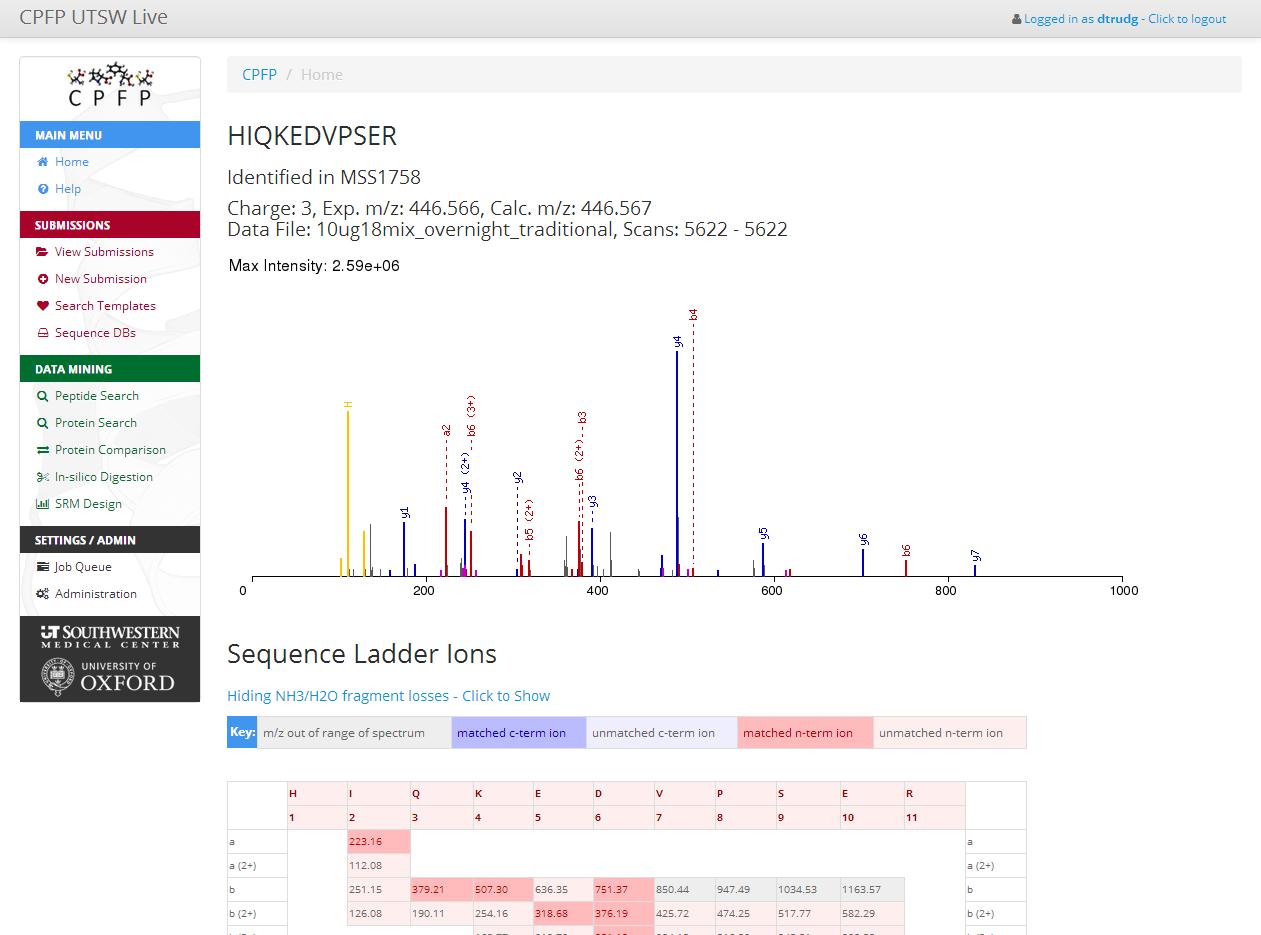
CPFP was created at the University of Oxford to satisfy the requirements of the two Central Proteomics Core Facilities. Development of the software continues at Oxford and at UT Southwestern Medical Center, where it is the primary analysis platform for the UTSW Proteomics Core.
At UTSW >90% of the shotgun proteomics data acquired is analyzed with CPFP, providing users with state-of-the-art results from a combination of database search engines.
CPFP is targeted at the needs of academic core facilities with multiple shotgun mass-spectrometry platforms. Although CPFP can be run on a single PC it's most useful for busier groups who need a centralized solution to data analysis, which exploits computing facilities and provides web-based access for staff and customers. Access to a bioinformatics expert or computing support staff comfortable with installing and maintaining large bioinformatics tools is necessary. A heavily used installation of CPFP can require many TB of disk space, and will require arrangements to backup results and the MySQL database, which can reach several 100s of GBs in size.
If you want to perform analyses with multiple search engines and combine results, but don't need to support a large number of users or work with huge datasets a simple single-PC package is more suitable. The stand-alone TPP pipeline has a continually improving web interface, and good community support.
If you want to perform analyses using cloud computing, HPC clusters, and need the flexibility to try and use non-TPP workflows we recommend looking at Galaxy-P. This project is extending the Galaxy package to support proteomics analyses, including those combining proteomic and genomic/transcriptomic data. Galaxy-P lacks CPFP's results database and viewers but supports a wide range of proteomics tools and is under very active development.
A demonstration server is maintained at UTSW so that you can try out CPFP without needing to install it or start an AWS instance.
This demonstration installation runs on a moderately specified Dell R415 12-core Opteron server, which is shared with other web applications. Submissions may be deleted without notice to maintain disk space, and very large jobs will be terminated if they interfere with other users / applications.
Demo Server
proteomics.swmed.edu/cpfpdemo/
CPFP is intended to be installed on Linux systems. It is tested on CentOS 6 / Scientific Linux 6, and the installation instructions reflect these distributions. The pipeline can be installed on other Linux distributions and OSX, but these installations are not fully documented or regularly tested.
Alternatively a CPFP installation can be started in the Amazon Web Services cloud. We provide an AWS EC2 image that provides an installation of CPFP that can be configured for stand-alone use, or as a master node that starts additional EC2 workers for data processing.
We no longer distribute .tar.gz archives of CPFP. Installation is via cloning the git source code repository which is maintained at SourceForge. We recommend cloning the master branch and then following the INSTALL instructions.
git clone git://git.code.sf.net/p/cpfp/code cpfp
less cpfp/INSTALL
The latest AMI is xxxxxxxx
Follow the CLOUD_INSTALL instructions that can be found in the git repository.
CPFP is released under the OSI approved Common Development and Distribution License (CDDL). Please see the LICENSE file and CDDL text.
If you use CPFP for published work please cite the following reference:
D. C. Trudgian, B. Thomas, S. J. McGowan, B. M. Kessler, M. Salek and O. Acuto, CPFP: a central proteomics facilities pipeline, Bioinformatics, 26(8), pp. 1131-1132, 2010. [Journal Link]
For Cloud CPFP (version 2.x and above):
D. C. Trudgian and H. Mirzaei, Cloud CPFP: A Shotgun Proteomics Data Analysis Pipeline Using Cloud and High Performance ComputingJ. Proteome. Res , Article ASAP, DOI: 10.1021/pr300694b, 2012. [Journal Link]
If you use the SINQ label-free quantitation functionality please cite:
D. C. Trudgian, G. Ridlova, R. Fischer, M. M. Mackeen, N. Ternette, O. Acuto, B. M. Kessler and B. Thomas, Comparative evaluation of label-free SINQ normalized spectral index quantitation in the central proteomics facilities pipeline.PROTEOMICS , 11 (14), pp. 2790-2797, 2011. [Journal Link]
CPFP has been built on tools from the ISB TPP, and includes / uses software from the NCBI and EBI. We are grateful to the authors of all software used by CPFP for their efforts in developing this software, and distributing their work freely.
We wish to acknowledge the Computational Biology Research Group, Medical Sciences Division, Oxford for use of their services in this project. We wish to thank OSSWatch and Matthew Loryman (University of Oxford Research Services) for aiding the release of this software.
Funding for the development of this software has been provided by various sources, including: